
Agent Memory Meets Graph: Introducing MemGraph
Your AI agent brilliantly diagnosed a Lambda-to-RDS connection storm last Tuesday. It identified the missing connection pooling, recommended the fix, and walked your team through implementation.
On Wednesday, the exact same pattern appeared in a different service. The agent started from zero.
This is the fundamental problem with AI agents today. They're stateless. Every conversation is a blank slate. The hard-won operational knowledge your team builds through months of incidents, optimizations, and architectural decisions — the agent forgets all of it the moment the session ends.
We built MemGraph to fix this.
The Memory Problem No One Talks About
Most AI agent platforms treat memory as an afterthought — a simple vector store that retrieves relevant documents. This approach has three fatal flaws:
No Relationships. Every memory is an island. A flat document store can't express that "before you resize an EKS node group, you must understand node affinity rules." There's no concept of prerequisite knowledge, conflicting approaches, or superseded procedures.
No Evolution. Knowledge grows stale. That gp2 resize procedure from 6 months ago sits alongside the current gp3 migration guide with equal weight. Outdated knowledge is worse than no knowledge — it leads agents to confidently give wrong answers.
No Signal. All memories are equal. A procedure validated 50 times in production ranks the same as one used once and never confirmed. There's no concept of earned trust, reinforcement, or contradiction.
Traditional RAG is a filing cabinet. You can find documents, but the cabinet doesn't know which documents are related, which are outdated, or which ones actually worked in practice. MemGraph is an experienced engineer's brain — it connects knowledge, prioritizes what's proven, and quietly deprecates what's no longer relevant.
Introducing MemGraph: Memory as a Knowledge Graph
MemGraph treats every piece of operational knowledge not as a document, but as a node in a graph — connected to other knowledge through typed, meaningful relationships.
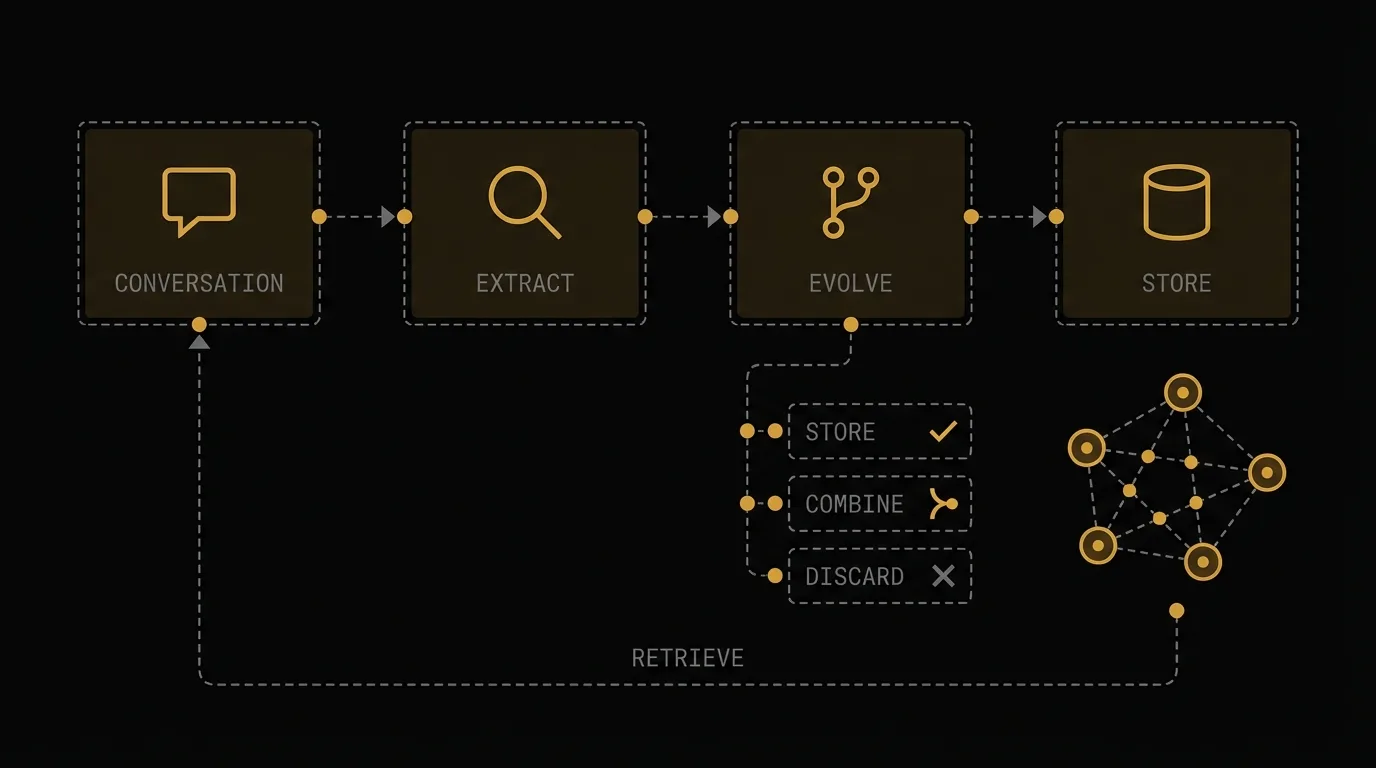
MemGraph architecture — Conversation to Extract to Evolve to Store pipeline with STORE, COMBINE, and DISCARD decision branches
Five Memory Types
Not all knowledge is the same. MemGraph classifies memories into five distinct types, each optimized for different retrieval patterns:
- Procedural — Step-by-step workflows and tool sequences
- Factual — Rules, constraints, and best practices
- Episodic — Success stories with reasoning
- Incident — Root cause analysis from real incidents
- Developer Pattern — Team-specific habits and preferences
Procedural Memory — The How-To Library
Reusable step-by-step workflows that solved real problems. These are the agent's playbook — battle-tested recipes that worked in your specific environment.
Task: Resize EKS node group with zero downtime
Solution:
1. Cordon existing nodes (prevent new pod scheduling)
2. Create new node group with target instance type
3. Wait for new nodes to reach Ready state
4. Drain old nodes (graceful pod eviction with PDB respect)
5. Verify all pods rescheduled on new nodes
6. Delete old node group
Context: Production EKS clusters with PodDisruptionBudgets configured
Factual Memory — The Rulebook
Hard constraints, best practices, and organizational rules. These prevent agents from suggesting non-compliant configurations, even if they'd be cheaper or simpler.
Task: RDS instance configuration requirements
Solution: Production RDS instances in us-east-1 MUST use Multi-AZ deployment.
Single-AZ is only permitted for dev/staging environments.
Minimum backup retention: 7 days for prod, 1 day for non-prod.
Context: Compliance requirement from SOC2 audit (2025-Q3)
Episodic Memory — The War Stories
Successful resolutions with the reasoning behind why they worked — enabling agents to apply similar reasoning to new problems.
Task: Reduce EBS costs for data processing workloads
Solution: Migrated 47 gp2 volumes to gp3 with custom IOPS/throughput tuning.
Result: 42% cost reduction ($8,400/month savings) with 15% better throughput.
Reasoning: gp2 IOPS scales linearly with volume size, forcing over-provisioning.
gp3 decouples IOPS from size, so you only pay for what you use.
Incident Memory — The Post-Mortems
Root cause analysis from real incidents, turned into reusable diagnostic patterns. When a similar pattern emerges, the agent immediately recognizes it and applies the proven fix instead of diagnosing from scratch.
Task: Lambda-to-RDS connection exhaustion (P1 incident)
Root Cause: Lambda functions creating new DB connections per invocation.
Under load (500 concurrent), exceeded RDS max_connections (150).
Solution: Implemented RDS Proxy with connection pooling.
Set max_connections_percent=70 to reserve headroom.
Added CloudWatch alarm on DatabaseConnections metric.
Developer Pattern Memory — The Team Playbook
Team-specific preferences, conventions, and tooling choices. These let agents adapt recommendations to match how your team actually works — not generic best practices, but your best practices.
Task: Infrastructure deployment preferences for Platform Team
Solution: Team uses Terraform modules exclusively (no raw CloudFormation).
Naming convention: {env}-{service}-{resource} (e.g., prod-api-rds).
Prefers blue-green over canary for stateful services.
Seven Relationship Types — The "Graph" in MemGraph
The real power isn't in individual memories — it's in how they connect. MemGraph supports seven typed relationships between memory nodes:
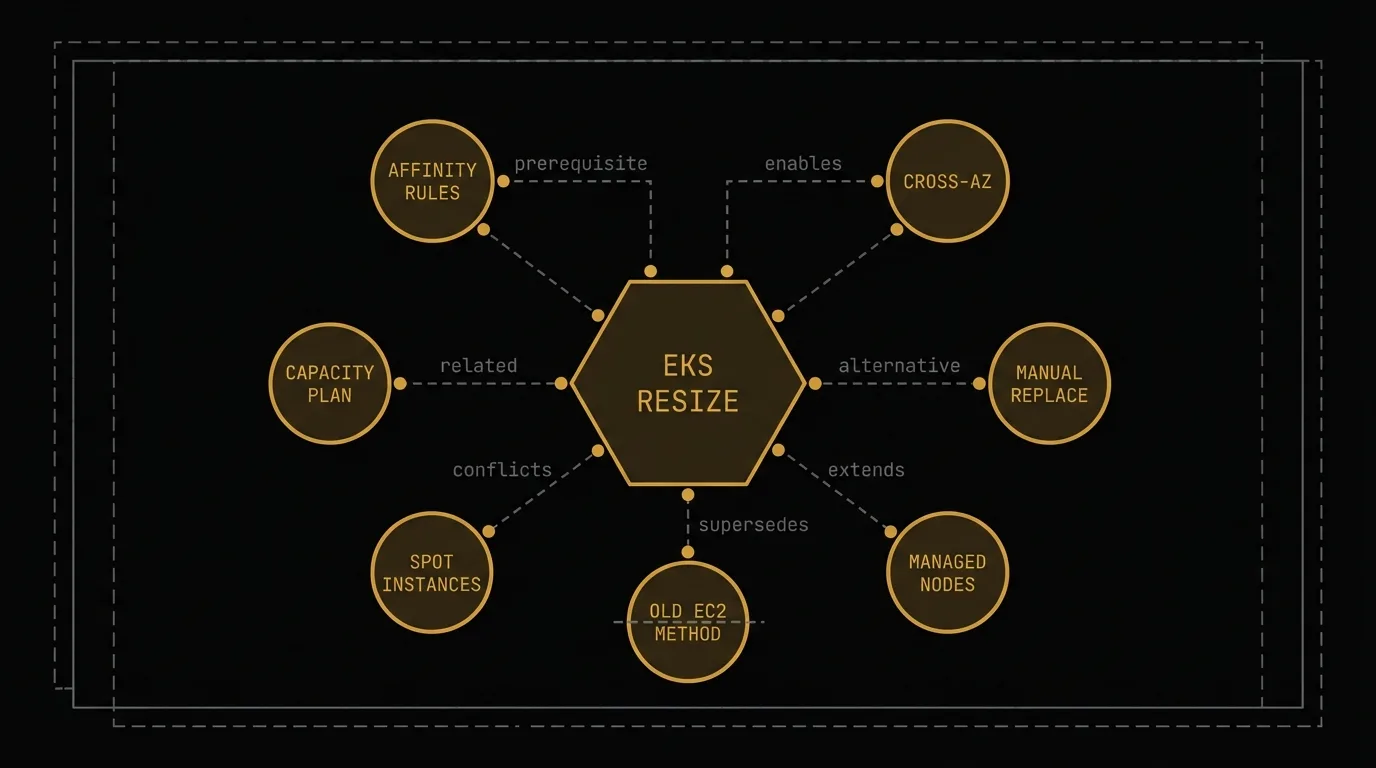
MemGraph relationship types — 8 nodes in a radial network graph showing prerequisite, enables, alternative, extends, supersedes, conflicts, and related edges
| Relationship | Meaning | Example |
|---|---|---|
| prerequisite | Must understand this before applying the memory | "Before resizing EKS nodes → understand PodDisruptionBudgets" |
| enables | This knowledge unlocks a more advanced capability | "Understanding VPC peering → enables cross-account access patterns" |
| alternative | Different approach to the same problem | "Spot instances vs. Reserved Instances for batch workloads" |
| extends | Adds depth or capability to existing knowledge | "Basic S3 lifecycle rules → extended with Intelligent Tiering" |
| supersedes | Replaces outdated knowledge | "gp3 migration guide supersedes old gp2 resize procedure" |
| conflicts | Contradicts — cannot apply both | "Spot instances conflict with guaranteed SLA requirements" |
| related | General semantic connection | "RDS optimization relates to connection pooling best practices" |
Why relationships matter: When an agent retrieves a memory about EKS node resizing, MemGraph automatically surfaces prerequisite knowledge about PodDisruptionBudgets. It flags that the old EC2-based resize method has been superseded. It warns that the spot instance approach conflicts with this workload's SLA requirements. The agent doesn't just get an answer — it gets the full context to apply it correctly.
The Evolution Pipeline — Memories That Learn
Most memory systems only append. Every new piece of knowledge gets added to an ever-growing pile. Over time, the pile becomes noise.
MemGraph curates. Every new memory goes through an LLM-driven evolution pipeline that decides how it should integrate with existing knowledge.
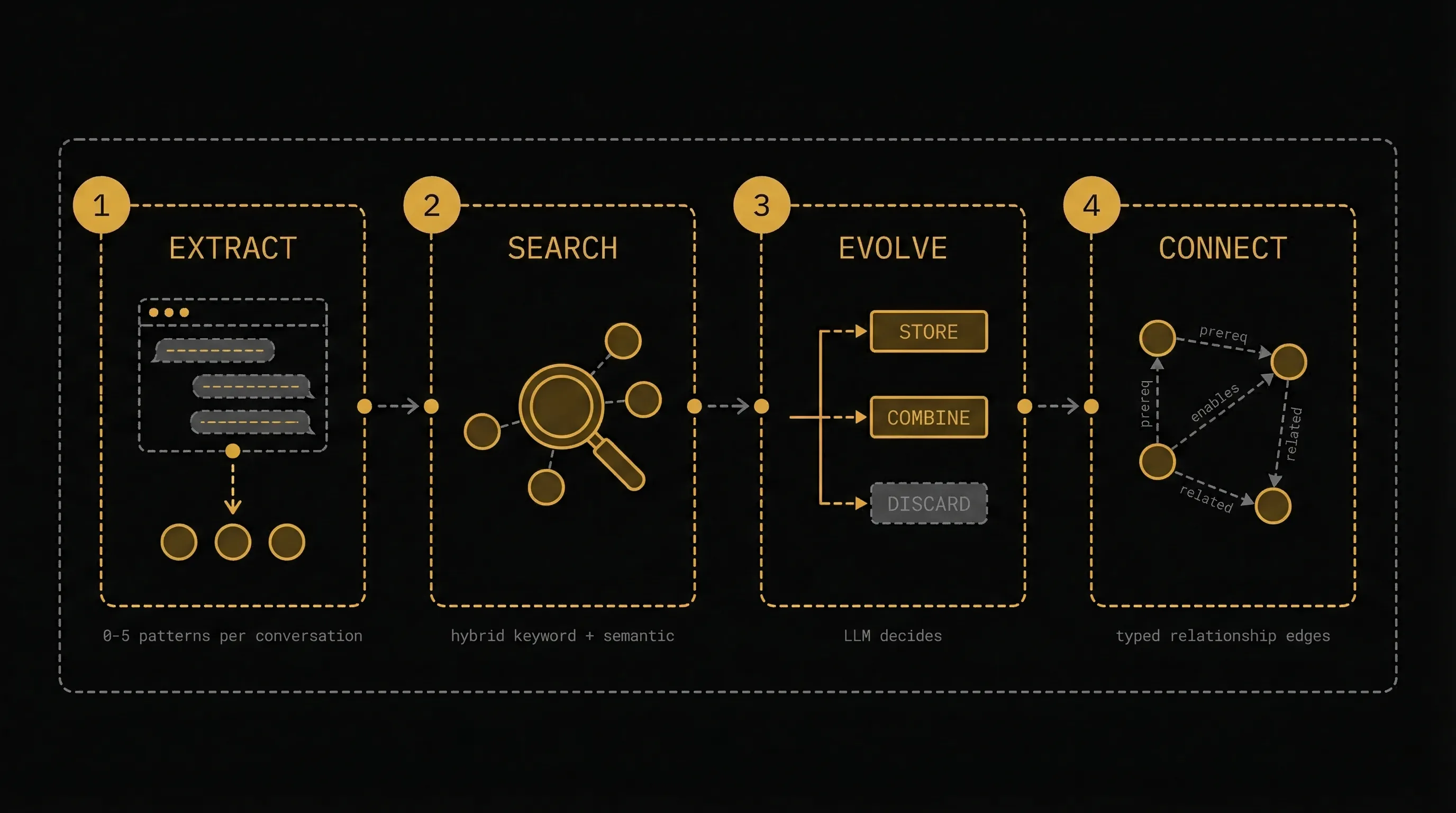
MemGraph evolution pipeline — four stages: Extract, Search, Evolve (STORE/COMBINE/DISCARD), Connect
1. Extract — After each conversation, an LLM analyzes the dialogue and extracts 0 to 5 reusable patterns — not raw chat logs, but distilled operational knowledge: the methodology that worked, the reasoning behind it, the context where it applies.
2. Search — For each extracted memory, MemGraph searches the existing knowledge graph for related memories using hybrid search — combining exact keyword matching (BM25) with semantic similarity (vector embeddings) through Reciprocal Rank Fusion.
3. Evolve — An LLM analyzes the new memory against search results and makes one of three decisions:
- STORE — This is genuinely new knowledge. Add it to the graph and build typed relationships to existing memories.
- COMBINE — This overlaps with something we already know. Merge them into a single, stronger, more complete memory.
- DISCARD — We already know this. Don't pollute the graph with duplicates.
4. Connect — For stored or combined memories, the LLM determines which existing memories have meaningful relationships — prerequisites, alternatives, conflicts — and builds typed edges. Keywords from related memories are enriched into the new node.
This is the architectural edge. Over time, MemGraph doesn't just grow — it gets sharper. Combined memories become more complete. Superseded memories get flagged. Validated procedures get reinforcement signals. The knowledge graph converges toward a refined, high-signal representation of your team's operational expertise.
Confidence Signals — Earned Trust, Not Static Scores
Every memory in MemGraph carries dynamic confidence signals that evolve over time:
- Access Count — How many times this memory has been retrieved. Frequently accessed memories are likely valuable.
- Reinforcement — How many times new evidence has confirmed this memory. Validated knowledge ranks higher.
- Contradiction — How many times new evidence has conflicted with this memory. Flags unreliable knowledge.
- Supersession — Whether this memory has been replaced by a newer, better version. Prevents serving outdated advice.
A procedure that's been reinforced 50 times gets a 5-50% score boost in search results. A memory that's been contradicted multiple times gets flagged for review. This is earned trust — the graph learns what works in your environment over time.
Hybrid Search — Finding the Right Memory at the Right Time
When an agent needs operational knowledge, MemGraph doesn't just do a simple text search. It combines three retrieval strategies:
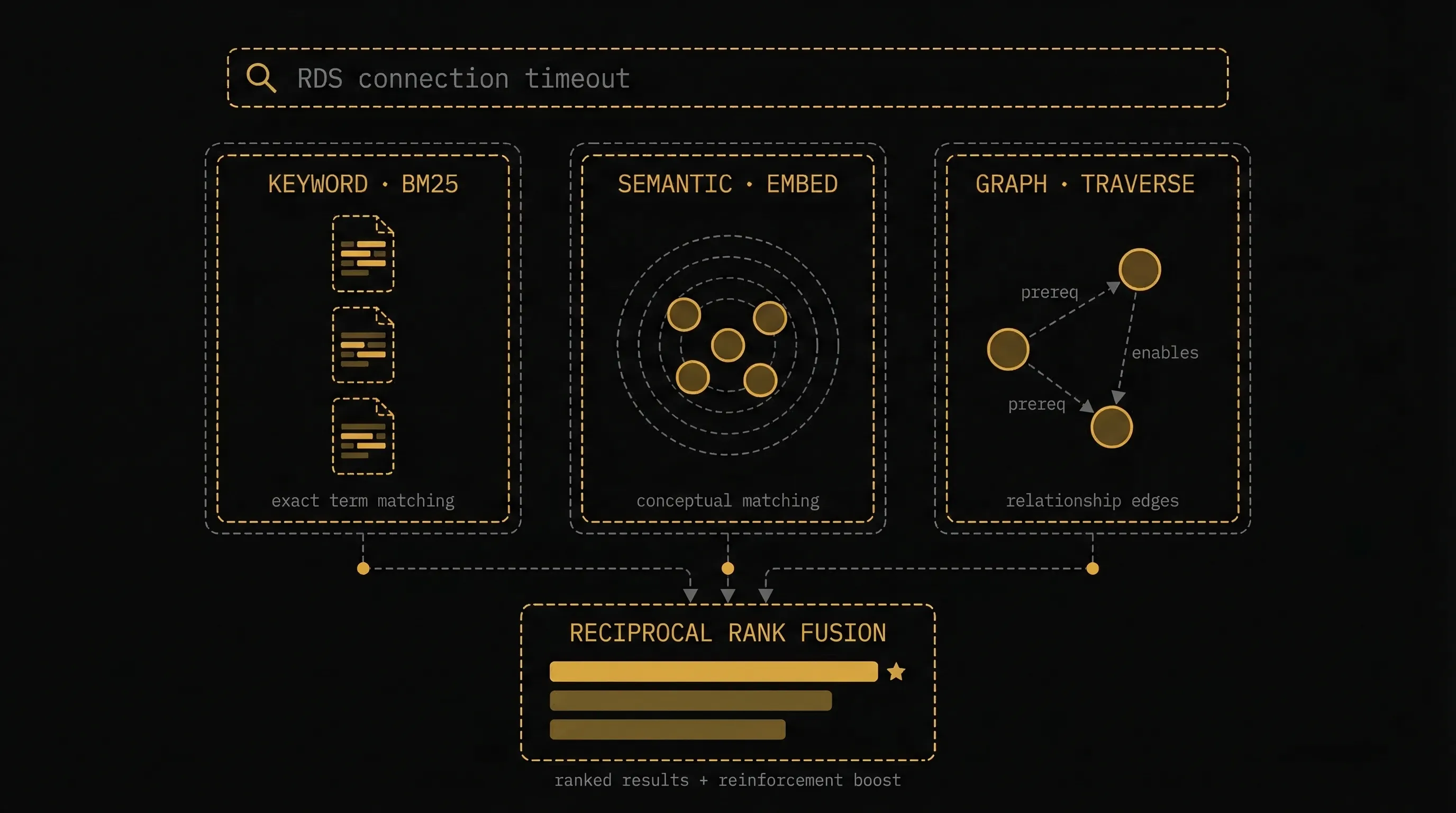
MemGraph hybrid search — three parallel lanes (Keyword BM25, Semantic Embeddings, Graph Traversal) merging via Reciprocal Rank Fusion
Keyword Search (BM25) — Sparse vector matching that finds memories containing exact terms from your query. When you search for "RDS connection timeout", it finds memories that specifically mention those words. Best for known error messages, service names, specific configurations.
Semantic Search (Embeddings) — Dense vector similarity that finds memories conceptually related, even if they use different terminology. A search for "database connection issues" finds memories about "connection pooling" and "RDS Proxy setup." Best for exploratory queries and "how do I..." questions.
Graph Traversal — When a relevant memory is found, MemGraph follows its prerequisite and enables edges to surface the full context. Finding "RDS Proxy Setup" automatically pulls in "VPC Security Group Configuration" (prerequisite) and "Multi-AZ Failover Optimization" (enables). Best for complete context retrieval.
The three strategies are combined using Reciprocal Rank Fusion (RRF), with an additional boost for memories with high reinforcement counts. The result: agents get the most relevant, battle-tested knowledge — with full context — every time.
Real-World Impact
Without MemGraph
You: @alex We're seeing connection timeouts on the orders-api RDS instance
Alex: I'll investigate the RDS connection timeout issue.
Let me check the current metrics...
[Runs CloudWatch queries from scratch]
[Analyzes connection count patterns]
[Researches possible causes]
[Eventually identifies connection pooling issue]
Time to diagnosis: 12 minutes
Same diagnosis your team did 3 months ago
Knowledge lost after session ends
With MemGraph
You: @alex We're seeing connection timeouts on the orders-api RDS instance
Alex: MemGraph match: This pattern matches a P1 incident from 3 months ago
(Lambda-to-RDS connection exhaustion, confidence: high, reinforced 12x)
Prerequisite: Checking if RDS Proxy is configured...
It's not — this is the same root cause.
Recommended fix (proven procedure):
1. Deploy RDS Proxy with connection pooling (max_connections_percent=70)
2. Update Lambda security groups for proxy access
3. Add CloudWatch alarm on DatabaseConnections metric
Time to diagnosis: 8 seconds
Battle-tested fix, validated 12 times across your infrastructure
Related: Also surfacing VPC security group prereqs
Use Cases in Production
Incident Memory — From 12-minute diagnosis to 8-second recognition. When similar incident patterns emerge, MemGraph immediately surfaces the proven root cause and fix — no re-diagnosis needed. The agent learns from every P1 your team resolves.
Cross-Conversation Context — Daily summaries and conversation memories let agents understand ongoing decisions: "The team agreed to freeze spot instance changes until after the SOC2 audit." No one has to re-explain context.
Personalized Operations — Per-user memory files store communication preferences, priorities, and constraints. The agent knows this SRE prefers Terraform, that security lead requires compliance-first framing, and the CTO wants executive summaries.
Team Pattern Recognition — MemGraph learns that your platform team uses Helm charts over raw manifests, prefers blue-green over canary, and has specific naming conventions. The agent adapts its suggestions to fit — not fight — your existing practices.
Under the Hood — Architecture
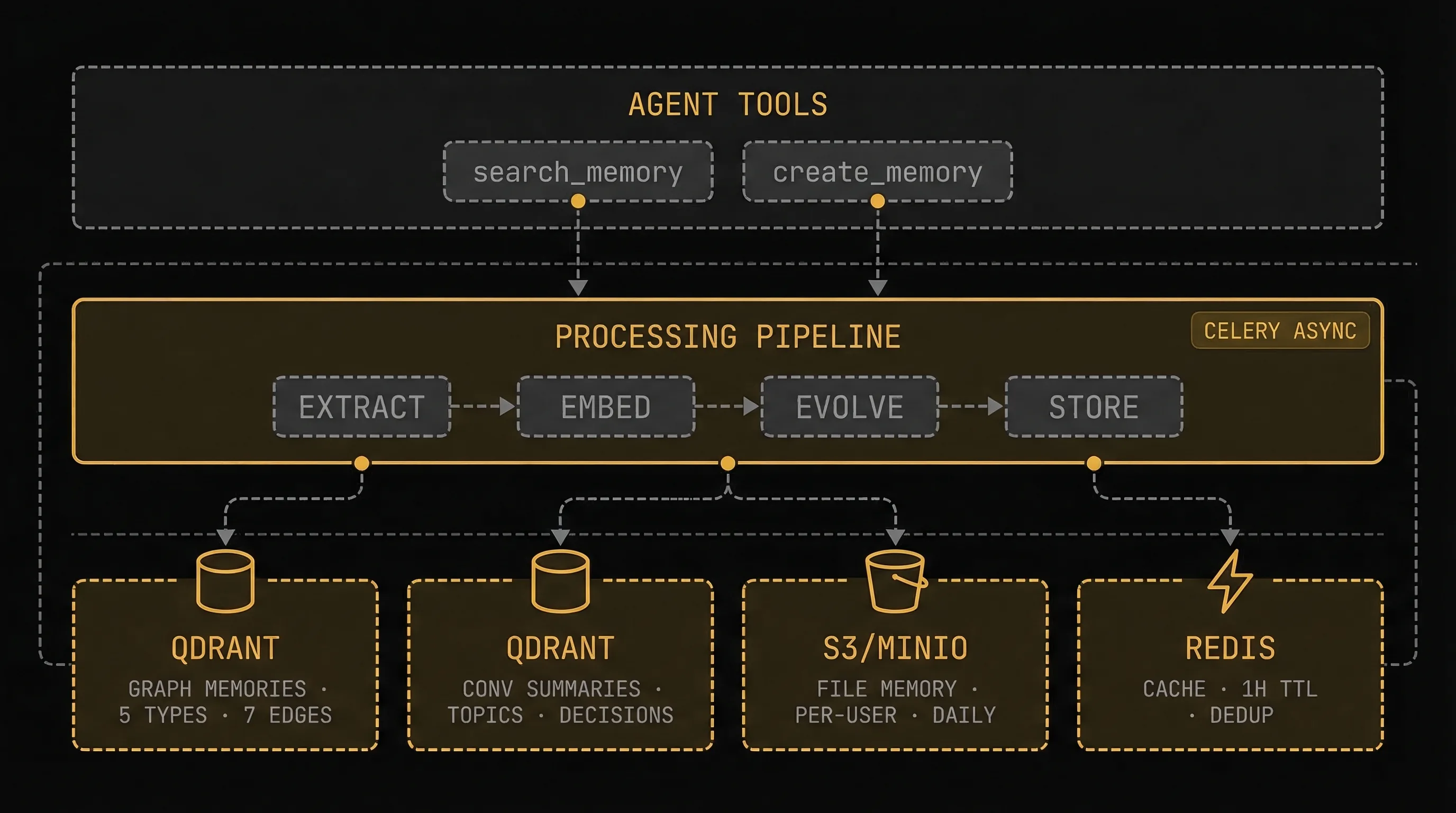
MemGraph storage architecture — three tiers: Agent Tools, Processing Pipeline (Celery), and four storage backends (Qdrant, Qdrant, S3/MinIO, Redis)
MemGraph is built on four storage backends, each optimized for its role:
| Layer | Backend | What It Stores | Why This Backend |
|---|---|---|---|
| Knowledge Graph | Qdrant (vector DB) | Memory nodes with typed relationships, dense + sparse vectors | Hybrid search (keyword + semantic) with metadata filtering |
| Conversation History | Qdrant (separate collection) | Topic summaries, key decisions, action items | Semantic retrieval across time windows (1-365 days) |
| Personal Context | S3/MinIO | Per-user preference files, per-workspace daily summaries | Durable, structured markdown with Redis caching (600s TTL) |
| Performance Cache | Redis | Search results, deduplication tracking | Sub-millisecond reads, automatic expiration |
Technical Details
Embedding Model: Amazon Bedrock Cohere Embed v4 — generates both dense vectors (semantic similarity) and sparse vectors (BM25-style keyword matching) in a single API call.
Search Algorithm: Reciprocal Rank Fusion (RRF) combines keyword and semantic search results, with a configurable reinforcement boost (5-50%) for validated memories.
Processing Pipeline: Fully async via Celery task queue. Memory extraction runs on high-priority workers with 300-second timeouts. Search results are cached in Redis for 1 hour to avoid redundant computation.
Deduplication: Content-hash-based dedup (MD5 normalized) with 24-hour TTL prevents the same knowledge from being stored multiple times across concurrent agent sessions.
Graph Traversal: When include_related=true, search results are enriched by following prerequisite and enables edges — surfacing the full context chain without requiring additional queries.
The Compound Effect
Here's what makes MemGraph fundamentally different from traditional memory systems:
Every conversation makes your agents smarter.
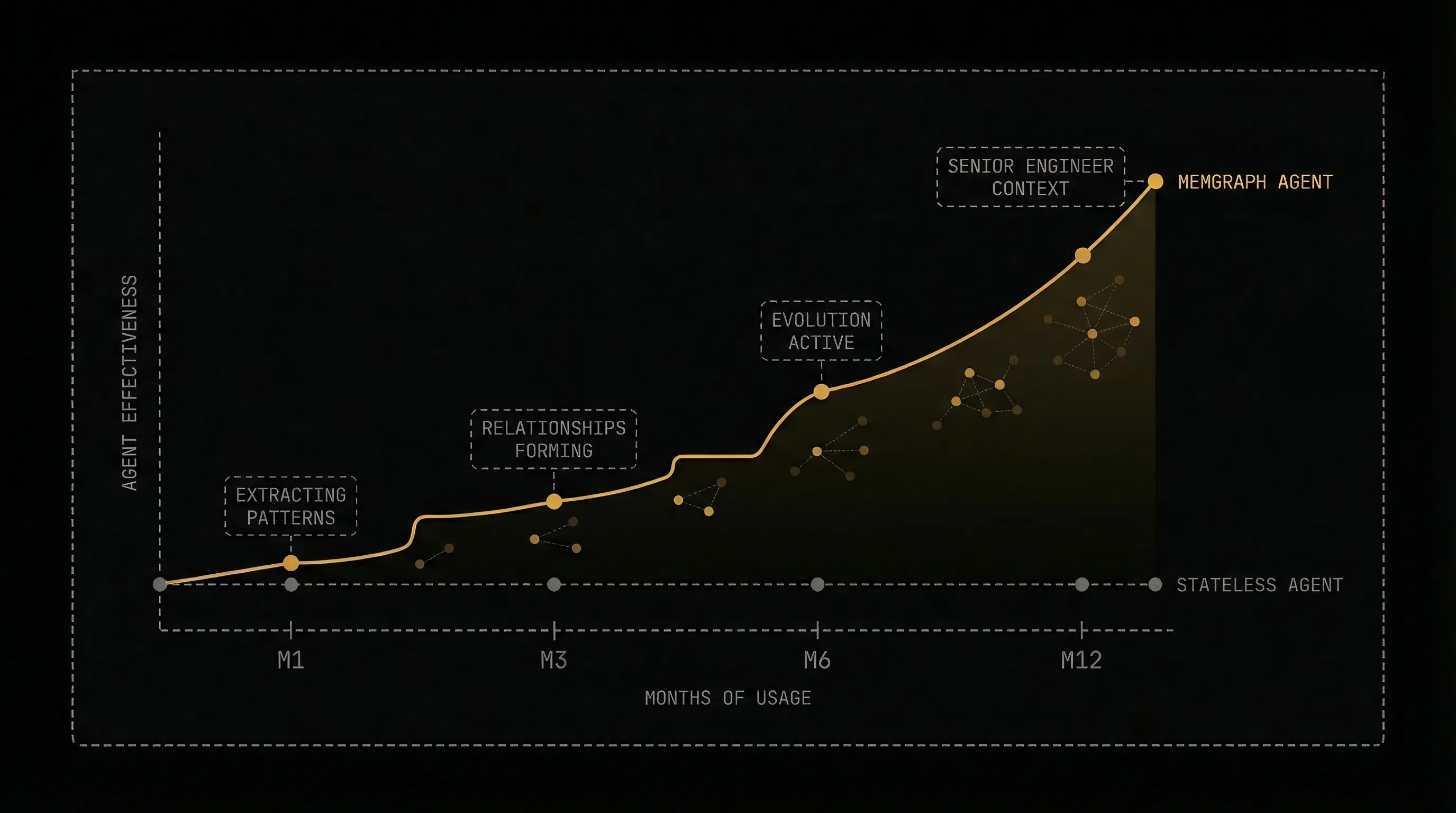
MemGraph compound learning effect — stateless agent (flat line) vs MemGraph agent (ascending curve) over 12 months
Unlike fine-tuning — which is expensive, batch-oriented, and risky — MemGraph evolves in real-time, per-workspace, with full auditability. You can inspect every memory node, trace every relationship, and understand exactly why the agent made a recommendation.
The graph starts sparse. After a month of operations, prerequisite chains emerge. After three months, the evolution pipeline is actively combining related memories and superseding outdated ones. After six months, your agents carry the operational context of a senior engineer who's been on your team from the start.
That's the compound effect. Not just remembering — connecting, validating, and refining knowledge with every conversation.
MemGraph is available today for all CloudThinker workspaces. Your agents are already learning from every conversation, building a knowledge graph unique to your infrastructure, your team's practices, and your operational history.